В «Фейсбуке» нам задали вопрос:
«Для работы с текстом мне нужно расшифровать 3 часа диктофонной записи. Пробовал загрузить аудиофайл с картинкой в YouTube и воспользоваться их расшифровщиком текста, но получается какая-то абракадабра. Подскажите, как можно решить это технически? Спасибо!
Александр Коновалов»
Александр, простое техническое решение есть – но результат будет зависеть исключительно от качества вашей записи. Поясню, о каком качестве речь.
За последние годы технологии распознавания русской речи сильно продвинулись вперед. Процент ошибок распознавания снизился до такого уровня, что иной текст стало проще «наговорить» в специальном мобильном приложении или интернет-сервисе, откорректировав вручную отдельные «очепятки» – чем целиком набирать весь текст на клавиатуре.
Но, чтобы искусственный интеллект системы распознавания смог проделать свою работу – пользователь должен проделать свою. А именно: говорить в микрофон четко и размеренно, избегать сильных фоновых шумов, по возможности использовать стереогарнитуру или выносной микрофон, прикрепленный к петлице (для качества распознавания важно, чтобы микрофон все время находился на одном расстоянии от губ, а вы сами говорили с одинаковой громкостью). Естественно, чем выше класс аудиоустройства – тем лучше.
Несложно придерживаться этих условий, если вы, вместо того, чтобы обращаться к интернет-сервису распознавания речи напрямую, применяете в качестве промежуточного устройства-посредника диктофон. К слову, такой «персональный секретарь» особенно незаменим, когда у вас нет доступа к онлайну. Естественно, лучше использовать хотя бы недорогой профессиональный диктофон, нежели записывающее устройство, встроенное в дешевый mp3-плеер или смартфон. Это даст гораздо больше шансов «скормить» полученные записи сервису распознавания речи.
Сложно, но можно уговорить соблюдать эти правила собеседника, у которого вы берете интервью (еще один совет: если у вас нет в комплекте выносного микрофона на прищепке – хотя бы держите диктофон рядом с собеседником, а не с собой).
А вот «законспектировать» на нужном уровне в автоматическом режиме конференцию или семинар – дело, на мой взгляд, практически нереальное (ведь вы не сможете контролировать речь спикеров и реакцию слушателей). Хотя достаточно интересный вариант: превращение в текст профессионально записанных аудиолекций и аудиокниг (если на них не накладывалась фоновая музыка и шумы).
Будем надеяться, что качество вашей диктофонной записи – достаточно высокое, чтобы ее удалось расшифровать в автоматическом режиме .
Если же нет – практически при любом качестве записи вы сможете провести расшифровку в полуавтоматическом режиме .
Кроме того, в ряде ситуаций наибольшую экономию времени и сил вам принесет, как ни парадоксально, расшифровка в ручном режиме . Точнее, тот ее вариант, который сам я использую уже с десяток лет. 🙂
Итак, по порядку.
1. Автоматическое распознавание речи
Многие советуют расшифровывать диктофонные записи на YouTube. Но этот метод заставляет пользователя тратить время на этапе загрузки аудиофайла и фоновой картинки, а затем – в ходе очистки итогового текста от меток времени. Между тем, это время несложно сэкономить. 🙂
Вы можете распознавать аудиозаписи прямо со своего компьютера, воспользовавшись возможностями одного из интернет-сервисов, работающих на движке распознавания Google (рекомендую Speechpad.ru или Speechlogger.com). Все, что нужно – проделать маленький трюк: вместо вашего голоса, воспроизводимого с микрофона, перенаправить на сервис аудиопоток, воспроизводимый вашим компьютерным проигрывателем.
Этот трюк называется программным стерео микшером (его обычно применяют для записи музыки на компьютере или ее трансляции с компьютера в интернет).
Стерео микшер входил в состав Windows XP – но был удален разработчиками из более поздних версий этой операционной системы (говорят, в целях защиты авторских прав: чтобы геймеры не воровали музыку из игр и т.п.). Однако стерео микшер нередко поставляется вместе с драйверами аудиокарт (например, карт Realtec, встраиваемых в материнскую плату). Если вы не найдете стерео микшер на своем ПК с помощью предлагаемых ниже скриншотов – попробуйте переустановить аудиодрайверы с CD-диска, который шел в комплекте с материнской платой – либо с сайта ее производителя.
Если и это не поможет – установите на компьютер альтернативную программу. Например – бесплатный VB-CABLE Virtual Audio Device : использовать его рекомендует владелец вышеупомянутого сервиса Speechpad.ru.
Первым шагом вы должны отключить для использования в режиме записи микрофон и включить вместо него стерео микшер (либо виртуальный VB-CABLE).
Для этого нажмите по иконке громкоговорителя в правом нижнем углу (возле часов) – либо выберите раздел «Звук» в «Панели управления». Во вкладке «Запись» открывшегося окна щелкните правой кнопкой мыши и поставьте птички напротив пунктов «Показать отключенные устройства» и «Показать отсоединенные устройства». Нажмите правой кнопкой по иконке микрофона и выберите пункт «Отключить» (вообще, отключите все устройства, отмеченные зеленым значком).

Нажмите правой кнопкой по иконке стерео микшера и выберите пункт «Включить». На иконке появится зеленый значок, что будет означать, что стерео микшер стал устройством по умолчанию.

Если вы решили использовать VB-CABLE – то тем же способом включите его во вкладке «Запись».

А также – во вкладке «Воспроизведение».

Второй шаг. Включите аудиозапись в любом проигрывателе (если нужно расшифровать аудиодорожку видеоролика – можно запустить и видеопроигрыватель). Параллельно загрузите в браузере Chrome сервис Speechpad.ru и нажмите в нем кнопку «Включить запись». Если запись достаточно высокого качества, вы увидите, как сервис на глазах превращает речь в осмысленный и близкий к оригиналу текст. Правда, без знаков препинания, которые вам придется расставить самостоятельно.

В качестве аудиопроигрывателя советую использовать AIMP, о котором будет подробнее рассказано в третьей подглавке. Сейчас лишь отмечу, что этот плеер позволяет замедлить запись без искажений речи, а также исправить некоторые другие погрешности. Это может несколько улучшить распознавание не слишком качественной записи. (Иногда даже советуют предварительно подвергать плохие записи обработке в профессиональных программах редактирования звука. Однако, на мой взгляд, это слишком трудоемкая задача для большинства пользователей, которые гораздо быстрее наберут текст вручную. 🙂)
2. Полуавтоматическое распознавание речи
Тут все просто. Если запись некачественная и распознавание «захлебывается» либо сервис выдает слишком много ошибок – помогите делу сами, «встроившись» в цепочку: «аудиоплеер – диктор – система распознавания».
Ваша задача: прослушивать в наушниках записанную речь – и параллельно надиктовывать ее через микрофон интернет-сервису распознавания. (Естественно, вам не нужно, как в предыдущем разделе, переключаться в списке записывающих устройств с микрофона на стерео микшер или виртуальный кабель). А в качестве альтернативы упоминавшимся выше интернет-сервисам можете использовать смартфонные приложения вроде бесплатной «Яндекс.Диктовки» либо функцию диктовки в iPhone с операционной системой iOS 8 и выше.
Отмечу, что в полуавтоматическом режиме вы имеете возможность сразу диктовать знаки препинания, расставлять которые в автоматическом режиме сервисы пока не способны.
Если у вас получится диктовать синхронно с воспроизведением записи на плеере – предварительная расшифровка займет практически столько же времени, сколько и сама запись (не считая последующих затрат времени на исправление орфографических и грамматических ошибок). Но даже работа по схеме: «прослушать фразу – надиктовать – прослушать фразу – надиктовать», – может вам дать неплохую экономию времени по сравнению с традиционным набором текста.
В качестве аудиоплеера рекомендую использовать тот же AIMP. Во-первых, с его помощью вы можете замедлить воспроизведение до скорости, на которой вам будет комфортно работать в режиме синхронной диктовки. Во-вторых, этот плеер умеет возвращать запись на заданное количество секунд: это бывает необходимо, чтобы лучше расслышать неразборчивую фразу.
3. Расшифровка диктофонной записи в ручном режиме
Вы можете установить на практике, что слишком быстро устаете от диктовки в полуавтоматическом режиме. Или делаете вместе с сервисом слишком много ошибок. Или, благодаря навыкам быстрого набора, гораздо легче создаете готовый исправленный текст на клавиатуре, чем с помощью диктовки. Или ваш диктофон, микрофон на стереогарнитуре, аудиокарта не обеспечивают приемлемое для сервиса качество звука. А может, у вас просто нет возможности диктовать вслух в своем рабочем или домашнем офисе.
Во всех этих случаях вам поможет мой фирменный способ расшифровки вручную (прослушиваете запись в AIMP – набираете текст в Word). С его помощью вы превратите запись в текст быстрее, чем это сделают многие профессиональные журналисты, чья скорость набора на клавиатуре аналогична вашей! При этом вы потратите гораздо меньше, чем они, сил и нервов. 🙂
Из-за чего, в основном, теряются силы и время в ходе расшифровки аудиозаписей традиционным способом? Из-за того, что пользователь совершает очень много лишних движений.
Пользователь постоянно протягивает руку то к диктофону, то к клавиатуре компьютера. Остановил воспроизведение – набрал прослушанный отрывок в текстовом редакторе – снова включил воспроизведение – отмотал неразборчивую запись назад – и т.д., и т.п.
Использование обычного программного плеера на компьютере мало облегчает процесс: пользователю приходится постоянно сворачивать/разворачивать Word, останавливать/запускать плеер, да еще елозить туда-сюда слайдером плеера, чтобы найти неразборчивый фрагмент, а затем вернуться к последнему прослушанному месту в записи.
Чтобы сократить эти и другие потери времени, специализированные IT-компании разрабатывают программные и аппаратные транскрайберы. Это достаточно дорогие решения для профессионалов – тех же журналистов, судебных стенографистов, следователей и т.д. Но, собственно, для наших целей требуются только две функции:
- возможность замедлить воспроизведение диктофонной записи без ее искажения и понижения тона (замедлить скорость воспроизведения позволяют многие плееры – но, увы, при этом человеческий голос превращается в монструозный голос робота, который сложно воспринимать на слух продолжительное время);
- возможность остановить запись или откатить ее на заданное количество секунд и вернуть обратно, не останавливая набор текста и не сворачивая окно текстового редактора.
В свое время я протестировал десятки аудиопрограмм – и нашел лишь два доступных платных приложения, отвечающих этим требованиям. Приобрел одно из них. Поискал еще немного для своих дорогих читателей 🙂 – и нашел замечательное бесплатное решение – проигрыватель AIMP , которым сам пользуюсь до сих пор.
«Войдя в настройки AIMP, найдите раздел Глобальные клавиши и перенастройте Стоп/Пуск на клавишу Эскейп (Esc). Поверьте, это наиболее удобно, поскольку не придется задумываться и палец не попадет случайно на другие клавиши. Пункты «Немного перейти назад» и «Немного перейти вперед» настройте, соответственно, на клавиши Ctrl + клавиши курсора назад/вперед (у вас на клавиатуре есть четыре клавиши со стрелками – выберите две из них). Эта функция нужна, чтобы заново прослушать последний фрагмент или перейти немного вперед.

Затем, вызвав эквалайзер, вы можете уменьшить значения «Скорость» и «Темп» – и увеличить значение «Питч». При этом Вы заметите, что скорость воспроизведения замедлится, но высота голоса (если хорошо подберете значение «Питч») – не изменится. Подберите эти два параметра так, чтобы вы практически синхронно успевали набирать текст, лишь изредка останавливая его.

Когда все будет настроено, набор будет занимать у вас меньше времени, и руки будут уставать меньше. Вы сможете расшифровывать аудиозапись спокойно и комфортно, практически не отрывая пальцев от набора текста на клавиатуре».
Могу только добавить к сказанному, что, если запись не очень качественная – вы можете попытаться улучшить ее воспроизведение, экспериментируя с другими настройками в «Менеджере звуковых эффектов» AIMP.
А количество секунд, на которое вам будет наиболее удобно перемещаться по записи назад или вперед с помощью горячих клавиш – установите в разделе «Плеер» окна «Настройки» (которое можно вызвать нажатием горячих клавиш «Ctrl + P»).

Желаю сэкономить побольше времени на рутинных задачах – и плодотворно использовать его для главных дел! 🙂 И не забудьте включить микрофон в списке записывающих устройств, когда соберетесь поговорить по скайпу! 😉
3 способа расшифровки диктофонной записи: распознавание речи, диктовка, ручной режим
Всем привет! Нормализация звука не проблема для того, кто умеет пользоваться Audacity даже на самом начальном уровне.
Начнем с определения.
Нормализовать звук — это, по простому говоря, так обработать его в аудиоредакторе, чтобы было приятно слушать, а именно:
- убрать фоновые шумы,
- выровнять громкость речи на протяжении всей звуковой дорожки,
- убрать резкие выбросы/пики громкости,
- убрать нежелательные звуки (кашель, например),
- сделать громкость записи такой, чтобы ее можно было комфортно слушать на всех типах компьютеров и мобильных устройств, выставляя громкость устройства на средний уровень.
Насколько это важно? Очень важно! Хорошее видео с плохим звуком – деньги на ветер. Видео «рулит» в интернет-маркетинге. Продаете ли вы через свой интернет-магазин, продвигаете ли свои услуги через сеть, строите ли корпоративный сайт, стремитесь раскачать свой канал в Youtube - везде нужно уметь сделать приличное видео. Но видео-то видео, а если у вас звуковое сопровождение будет тихое, глухое, с шумами, другими дефектами, то считайте, что вся работа насмарку. Никто такое видео далее 10 секунд не станет продолжать смотреть.
Сразу скажу, что если вы уповаете на свою суперсовременную дорогую профессиональную видеокамеру, то это напрасно. Шумы-то она запишет даже лучше чем смартфон. Так что на 100% «вытянуть» звук первоклассным «железом» не получится.
Профессионалы пользуются для этого звуковыми редакторами. Берут отдельно аудиодорожку и правят ее. В этом посте я научу вас, как пользоваться Audacity для нормализации звука.
Почему именно Audacity? Потому, что это:
- Специализированная программа – аудиоредактор звуковых файлов.
- Достаточно мощная для того, чтобы сделать со звуком что угодно.
- Бесплатная.
- Достаточно простая в освоении. Особенно когда дело касается стандартных не сложных операций со звуком.
Ну, давайте начнем.
Из этой статьи вы узнаете:
Для того, чтобы все было максимально приближенно к реальной жизни и понятно, возьмем видеозапись, сделанную на самый обычный смартфон – htc one v. Видео он снимает разрешением HD. На сегодня это уже не нечто запредельное, а стандарт. Звук захватывает как смартфон – если близко, то хорошо, если на расстоянии, то уже посредственно.
Итак, наша самая первая задача:
Как извлечь звук из видео в отдельный звуковой файл
Способов — масса. Чтобы не загромождать пост второстепенными подробностями, вкратце расскажу всего про три. Выберете удобный для себя.
- Посредством бесплатной программы Freemake Video Converter
- Посредством платной программы Total Video Converter
- Посредством имеющего у вас видеоредактора. А иметься он у вас должен. Особенно если весь или часть вашего бизнеса — в интернете. Особенно если вы регулярно снимаете и выкладываете видео на ваш сайт. Конечно если вы хотите выкладывать хорошее видео, чтобы его смотрели много людей.
Первые два пункта подробно объяснять не стоит. Там все совершенно несложно, но если будут проблемы – пишите, объясню.
Вот на видеоредакторе остановлюсь поподробнее. В смысле как извлечь звук из видео с его помощью. Видеоредакторов тоже очень много. Я пользуюсь одним из самых популярных – Sony Vegas.
Копируем отснятое видео из смартфона на компьютер.
Открываем видеоредактор.
Через меню Файл – Открыть открываем видеофайл.
 и выбираем формат сохраняемого файла mp3. Нажимаем на Custom…
и выбираем формат сохраняемого файла mp3. Нажимаем на Custom…
 и выбираем параметры сохранения. Рекомендую выбрать Моно, битрейт 128 kbps и частоту 44 100 Hz.
и выбираем параметры сохранения. Рекомендую выбрать Моно, битрейт 128 kbps и частоту 44 100 Hz.
 Выбираем папку сохранения и желаемое имя сохраняемого mp3 файла.
Выбираем папку сохранения и желаемое имя сохраняемого mp3 файла.
Все аудиодорожку мы отдельно сохранили и теперь начнем нормализовать звук . Я распишу все пошагово.
Шаг 1. Первичное применение плагина Hard Limiter
На записанном звуке могут оказаться пики-выбросы по громкости. Если их не уменьшить, то они здорово раздражают или могут даже оглушать. Это может быть и кашель, и внезапно громко передвинутый стул, сигнал рядом проезжающей машины и так далее. Поэтому:
Кликаем по области управления свойствами дорожки левой кнопкой мышки и тем самым выделяем всю дорожку
 Затем идем в меню Эффекты-Hard Limiter… и ставим вот такие параметры
Затем идем в меню Эффекты-Hard Limiter… и ставим вот такие параметры

Кликаем ОК. Готово.
Шаг 2. Нормализация звука
Обычно запись с микрофонов, смартфонов, диктофонов получается тихой для того, чтобы ее прямо вот в таком виде выложить в виде видео на ютюбе. Значит нам нужно поднять громкость звука. Но желательно сделать это так, чтобы звук был поднялся, но не выше заданного предела. Для этого применяется плагин Нормировка сигнала. Он увеличивает громкость, но так, что максимальная амплитуда – фиксированная. Для этого идем в меню Эффекты-Нормировка сигнала… Ставим в окошке -3.0 db.

Жмем ОК. Смотрим результат.
Шаг 3. Обработка аудиофайла плагином Компрессор…
Продолжаем пользоваться Audacity для нормализации звука и на этом шаге освоим плагин Компрессор… Обращаю ваше внимание, что обрабатывать дорожку нужно именно в таком порядке пошагово, не путая и не перескакивая. Для чего нужен Компрессор…? Компрессор усредняет, уменьшает разницу между самыми тихими и самыми громкими участками. Бывает, человек говорит в микрофон то громче, то тише и при слишком большой разнице слушать такую запись некомфортно. После обработки компрессором, громкость голоса становится более ровной, без скачков.
Итак идем в Эффекты-Компрессор… Ставим вот такие же параметры
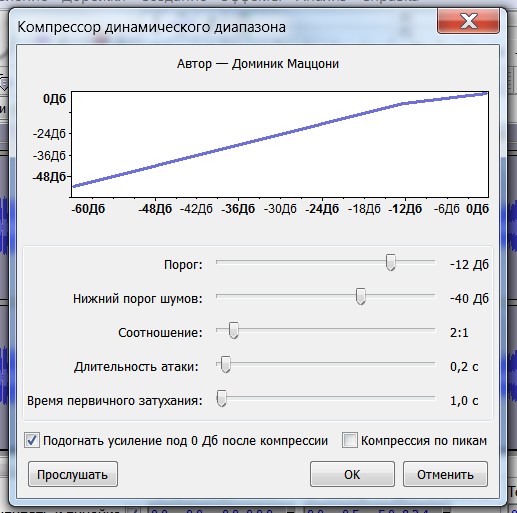
и жмем ОК. Радуемся результату.
Шаг 4. Финишная обработка плагином Hard Limiter…
Как бы хорошо ни обрабатывал звук Компрессор, у его алгоритма тоже есть недостатки и при определенных условиях он снова выделяет пики. Чтобы избежать этого, еще раз обработайте дорожку плагином Hard Limiter…, только ставьте уровень не -10, как в первый раз, а -2.0 db.
Вот вобщем и всё. В большинстве случаев этих 4 шагов достаточно. Теперь рассмотрим более сложные случаи, а именно:
- если предыдущие плагины – Нормировка сигнала… и Компрессор… — не совсем хорошо справились с нормализацией громкости по всей длине аудиодорожки
- и если запись шла при высоком уровне фоновых шумов – рядом работал холодильник, шумел вентилятор, какое-нибудь гудение и тому подобное.
Ручное выравнивание громкости отдельных участков аудиодорожки
Для этого применим простой плагин Усиление сигнала. Он действует как ручка громкости. На этом этапе применение его оправдано, так как звук уже прогнан через Нормировку сигнала… и Компрессор… и в целом представляет собой выровненную без скачков диаграмму. Только, как видите она глобально разная на больших участках. С таким «раскладом» предыдущие плагины не всегда хорошо справляются и поэтому вот сейчас исправим это руками. Замечу, что такая ситуация бывает нечасто.
Итак, выделяем ту часть звуковой дорожки, где уровень сигнала явно ниже. Идем в меню Эффекты-Усиление сигнала… и подбором уровня усиления добиваемся выравнивания фрагментов аудиодорожки по громкости. Посмотрите на видео, как это происходит.
Как убрать шум из записи
Обратите внимание, что сейчас я буду объяснять как бороться именно с непрерывным фоновым шумом. Если вдруг во время непосредственно записи кто-то кашлянул, чихнул, что-то упало – это все не фоновый шум и если есть желание его убрать, то делать это нужно другими способами. А сейчас мы будем убирать именно фоновый шум. Итак, чтобы убрать шум из аудио, нужно найти на аудиодорожке участок тишины, выделить его и внимательно прослушать. Желательно, чтобы он содержал только ровный фоновый шум, без щелчков и других «выпадающих» или выделяющихся кусочков. Чем лучше мы подберем такой фрагмент, тем качественнее программа справится с зачисткой всей аудиодорожки.
Для этого визуально выбираем на диаграмме участок с нулевой или около того амплитудой и выделяем его мышью. Кликаем на кнопку Play в панели кнопок Audacity и внимательно слушаем. Если на фоновом шуме есть другие единичные звуки, то стараемся найти и выделить фрагмент без них.
Найдя наилучший фрагмент, выделяем его. Идем в меню Эффекты-Удаление шума-Создать модель шума.
Затем выделяем всю дорожку. Идем в меню Эффекты-Удаление шума. Оставляем вот эти параметры

Единственный параметр, с которым можно поэкспериментировать, это Подавление шума. Самое первое поле. Советую оставаться в пределах 12-24 db. Если сделать ниже 12, то шум может снизиться совсем незначительно. Если сделать выше 24, то могут появиться искажения на оставшихся участках со звуком.
Смотрим видео, где я все это делаю:
Вот и всё. Аудиодорожка нормализована, осталось сохранить ее в виде файла.
Сохранение обработанной Audacity дорожки в отдельный аудиофайл
Делается это через меню Файл-Экспортировать… Обращаю ваше внимание, что через меню Файл-Сохранить проект… вы сохраните аудиозапись именно в формате Audacity и только. Для того, чтобы сохранить в формате mp3 или wav нужно пользоваться именно Экспортировать… Далее все просто. Выбираете желаемый тип файла. Если необходимо – кликаете Параметры… и задаете нужные параметры. Например, если вы делаете экспорт в mp3, то вы сможете выбрать через Параметры качество звука. Рекомендую не делать его ниже 80 кбит/с и выше 128 кбит/с. Это для голоса, конечно. Если вы писали музыку и вам необходимо максимальное качество звучание, то можете поставить даже 320 кбит/с. Имейте только в виду, что чем выше битрейд (это качество звука), тем большего размера будет получаться итоговый файл.
Итак, из этого поста вы узнали как пользоваться Audacity в части нормализации звука.
Дополнено в декабре 2018 г. — Эта статья написана в 2014 году. За прошедшие 5 лет, к концу 2018го, накопился опыт, выявились тонкости и приемы, которые:
- упрощают процедуру,
- уменьшают время на обработку звука и
- заметно улучшают качество итогового звука
Я часто записываю информацию на диктофон. Но в результате получается звук очень тихий и с шумами. Необходимо улучшить качество сделанных записей. Для этого я буду использовать Adobe Audition CS5.5.
0. Получение файла
После того как была произведена запись, файл необходимо скопировать на компьютер. Обычно для этого используются специализированные программы, входящие в комплект поставки диктофона или телефона.
Меню"File" > "Open..." и появившемся окне выбираем обрабатываемый файл.
Отмечу, что Adobe Audition поддерживает большое количество форматов звуковых файлов.
2. Перевод в mono (если необходимо)
Некоторые платы захватывают монозвук только в стереорежиме Stereo. Во-первых, эта лишняя трата места (каналы дублируются). Во-вторых, обрабатывать два раза одно и то же (для каждого канала) нет смысла. Поэтому такие записи необходимо перевести в моно.
 |
| Стереозапись |
- Выбрать "Edit" > "Extract Channels to Mono Files", а затем сохранить одну из двух полученных дорожек в файл.
- Выбрать "Edit" > "Convert Sample Type", а затем изменить параметр Channels на mono. Можно также изменить частоту на 48 000 Гц (качество эта процедура не улучшит, но сделает запись совместимой с форматом DVD).

Таким образом, получаем монозапись:
 |
| Монозапись |
Настоятельно рекомендуется проводить обработку звука в разрешении большем, чем разрешение конечного результата - это позволит повысить точность выполнения всех промежуточных преобразований и положительно скажется на качестве звука.
Если для исходного материала и результата используется 16 бит, то рекомендуется все промежуточные операции проводить с разрешением 32 бита. Для этого перед началом обработки звука нужно преобразовать его в формат 32 бита, а по окончании обработки - обратно в 16 бит. Если исходный материал и результат по 32 бита, то увеличить разрешение не получится (32 бита - максимум).
Сделать это можно при помощи "Edit" > "Convert Sample Type", частоту дискретизации (Sample Rate) и каналы (Channels) оставляем такими же (Same as Source), а для разрядности (Bit Depth) выбираем 32 или 16 бит, соответственно.

4. Удаление постоянной составляющей
Следующий этап - удаление постоянной составляющей. Часто при записи звука аппаратура добавляет в звуковой выход некоторую постоянную составляющую. Данное явление приводит к тому, что после записи "синусоида" оцифрованного звука смещена вверх или вниз от центра - нулевого уровня, что может создать сложности при дальнейшей обработке звука.
Чтобы убрать постоянную составляющую в звуковом файле, используется функция"Effects" > "Amplitude and Compression" > "Normalize (process)", выставите DC Bias Adjust 0.0%:

5. Удаление фонового шума
Наиболее важный этап, на мой взгляд, удаление фонового шума. Удаление шума состоит из двух подэтапов. Сначала нужно найти часть записи, в которой нет никаких звуков - только шум. Как правило, такие участки есть перед началом записи или в самом её конце, можно также использовать паузу посреди записи. Чем длиннее такой фрагмент, тем лучше можно определить профиль шума. Поэтому в конце записи я на пару минут оставляю диктофон в помещение, где производилась сама запись.
Открываем форму обработки шума: "Effects" > "Noise Reduction / Restoration" > "Noise Reduction (process)". В ней делаем следующие действия:
- Жмём "Capture Noise Print", тем самым захватывая профиль шума. После этого в окне отобразится график шума.
- Воспроизводим файл, нажимая "Select Entire File" и "Play". Пока звучит запись мы на лету можем регулировать шумоподавление.
- Регулировка шумоподавления осуществляется передвижением точек синей линии. Двигая их вверх-вниз необходимо добиться наилучшего звучания записи без шума.
- Как только найден подходящий фильтр, его можно и нужно сохранить в файл. Во-первых, это позволяет избежать повторной настройки. Во-вторых, в новых записях возможно не будет фрагмента, который содержат только шум.
- На последнем шаге необходимо применить фильтр ко всему файлу, нажав кнопку "Apply". Если требуется применить фильтр только к определённой части записи, то из окна "Effect - Noise Reduction" можно переключится в основное окно и выделить необходимый фрагмент.

Нужно быть внимательным при выборе части звукового файла, в которой только шум и нет никаких звуков. Дело в том, что если в этом фрагменте окажется какой-то звук, то Adobe Audition будет удалять все похожие звуки по всей записи. Это приведет к появлению неприятных "металлических" призвуков, особенно заметных на музыкальных фрагментах. Также вы можете судить о наличии таких звуков в вашем фрагменте по изломам и всплескам на спектре шума в окне Noise reduction. Обычно график спектра шума представляет собой плавно меняющуюся линию без резких изломов, возможно, с одним или несколькими всплесками в области высоких частот (справа) (в области высоких частот шумы в звуковом тракте видеотехники особо велики: свист и шипение). Если в результате удаления шума возникли такие призвуки, попробуйте отменить операцию ("Edit" > "Undo noise reduction") и повторить всё с самого начала, начиная с выделения фрагмента звука с шумом. Образец шума и очищаемый от шума звуковой фрагмент могут храниться в разных файлах, эти файлы могут иметь разную разрядность: необходимо только чтобы у этих файлов была одинаковая частота дискретизации и количество каналов.
Функция подавления шума в Adobe Audition является универсальной и позволяет с легкостью удалять почти любые шумы. В результате файл, очищенный от шумов, звучит значительно лучше.
6. Удаление ненужных фрагментов
Понятно, что некоторые фрагменты записи будут просто не нужны. Их следует удалить.
7. Удаление пауз
Ставилась задача: Преобразовать плохую аудиозапись с диктофона в текст на бумаге.
Первая часть.
Установив аудио редактор правим фонограмму.
С помощью редактора удалось улучшить аудиозапись до разборчивого состояния.
Использовался «эффекты»
- «компрессор
» без галочки «компрессия по пикам
»
Можно безболезненно повторять эту процедуру до четырех раз без потери качества сигнала.
Тонкие настройки рассматривать не будем. Это объёмный сложный раздел, требующий вдумчивого подхода и многих часов работы.
Можно поступить проще, усилив сигнал на 20 дб. Больше не советую, т.к. появятся искажения на ограничениях пиков. Компрессия дает лучший результат.
Порядок работы с аудио редактором:
В меню «Файл» - «импортировать» - «звуковой файл»
из открывшегося окна загружается ваша аудиозапись.
Предпочтительно работать с несжатыми .
WAV
файлами но, к сожалению, простые диктофоны в таком формате файлы не пишут и сразу сжимают в .
MP3
, что ведет к большой потере информации.
В окне аудио редактора сразу появится осциллограмма фонограммы.
Наведя мышку на интересующий участок, нажмите левую кнопку и проведите, не отпуская вправо или влево.
Выделится участок фонограммы, который вы можете прослушивать нажатием клавиши «пробел».
Подведя мышку к краю отмеченного участка, увидите указующий перст
, с помощью которого можно раздвинуть участок просмотра.
Увеличивая или уменьшая масштаб записи можно визуально выделять и редактировать интересующий фрагмент.
Задействованы все привычные сочетания клавиш, как в текстовом редакторе.
Для работы с полной фонограммой имеются большие кнопки вверху. А внизу в окошечках показаны счетчики начала и конца фрагмента в секундах. Их можно править вручную.
Можно сделать копию фонограммы и мучить её в новом окне. Так даже лучше.
Можно в том же окне создать новый трек, поместив туда дубль, который предстоит улучшать.
«Дорожки»- «создать» - «монофонические дорожки»
Полезно дополнительно «дорожки» - «создать» - «дорожка пометок»
, где помечается выделяемый для работы участок фонограммы,
Проигрывать варианты редактируемых дорожек, сравнивать качество звучания.
Не забыв перед этим в левой части окна дорожки нажать на «тихо»
и прослушивать только «соло»
интересующей дорожки.
Думаю, вам понравится эта фишка.
Дорожку можно свернуть, убрать, удалить.
Если редактирование закончено и всё устраивает, тогда сохраняем результат
«файл» - “
Export
select
audio”
сохранить в формате.WAV
Для сохранения в.MP3 нужно прикрутить специальный плагин. Думаю, нет смысла.
Вторая часть.
Пишем аудио на бумагу.
Облом - с!
С микрофона пишет, а из файла толком не работает.
Причина: Война гигантов.
Корректное распознавание только из файлов.HTML5, да и то очень криво.
Потратил весь день и оставил эту затею.
Отрицательный результат тоже результат.
Кто-то, прочитав статью, сэкономит время.
В довершение, маленький
Я часто записываю информацию на диктофон. Но в результате получается звук очень тихий и с шумами. Необходимо улучшить качество сделанных записей. Для этого я буду использовать Adobe Audition CS5.5.
0. Получение файла
После того как была произведена запись, файл необходимо скопировать на компьютер. Обычно для этого используются специализированные программы, входящие в комплект поставки диктофона или телефона.
Меню"File" > "Open..." и появившемся окне выбираем обрабатываемый файл.
Отмечу, что Adobe Audition поддерживает большое количество форматов звуковых файлов.
2. Перевод в mono (если необходимо)
Некоторые платы захватывают монозвук только в стереорежиме Stereo. Во-первых, эта лишняя трата места (каналы дублируются). Во-вторых, обрабатывать два раза одно и то же (для каждого канала) нет смысла. Поэтому такие записи необходимо перевести в моно.
|
| Стереозапись |
- Выбрать "Edit" > "Extract Channels to Mono Files", а затем сохранить одну из двух полученных дорожек в файл.
- Выбрать "Edit" > "Convert Sample Type", а затем изменить параметр Channels на mono. Можно также изменить частоту на 48 000 Гц (качество эта процедура не улучшит, но сделает запись совместимой с форматом DVD).
Таким образом, получаем монозапись:
|
| Монозапись |
Настоятельно рекомендуется проводить обработку звука в разрешении большем, чем разрешение конечного результата - это позволит повысить точность выполнения всех промежуточных преобразований и положительно скажется на качестве звука.
Если для исходного материала и результата используется 16 бит, то рекомендуется все промежуточные операции проводить с разрешением 32 бита. Для этого перед началом обработки звука нужно преобразовать его в формат 32 бита, а по окончании обработки - обратно в 16 бит. Если исходный материал и результат по 32 бита, то увеличить разрешение не получится (32 бита - максимум).
Сделать это можно при помощи "Edit" > "Convert Sample Type", частоту дискретизации (Sample Rate) и каналы (Channels) оставляем такими же (Same as Source), а для разрядности (Bit Depth) выбираем 32 или 16 бит, соответственно.
4. Удаление постоянной составляющей
Следующий этап - удаление постоянной составляющей. Часто при записи звука аппаратура добавляет в звуковой выход некоторую постоянную составляющую. Данное явление приводит к тому, что после записи "синусоида" оцифрованного звука смещена вверх или вниз от центра - нулевого уровня, что может создать сложности при дальнейшей обработке звука.
Чтобы убрать постоянную составляющую в звуковом файле, используется функция"Effects" > "Amplitude and Compression" > "Normalize (process)", выставите DC Bias Adjust 0.0%:
5. Удаление фонового шума
Наиболее важный этап, на мой взгляд, удаление фонового шума. Удаление шума состоит из двух подэтапов. Сначала нужно найти часть записи, в которой нет никаких звуков - только шум. Как правило, такие участки есть перед началом записи или в самом её конце, можно также использовать паузу посреди записи. Чем длиннее такой фрагмент, тем лучше можно определить профиль шума. Поэтому в конце записи я на пару минут оставляю диктофон в помещение, где производилась сама запись.
Открываем форму обработки шума: "Effects" > "Noise Reduction / Restoration" > "Noise Reduction (process)". В ней делаем следующие действия:
- Жмём "Capture Noise Print", тем самым захватывая профиль шума. После этого в окне отобразится график шума.
- Воспроизводим файл, нажимая "Select Entire File" и "Play". Пока звучит запись мы на лету можем регулировать шумоподавление.
- Регулировка шумоподавления осуществляется передвижением точек синей линии. Двигая их вверх-вниз необходимо добиться наилучшего звучания записи без шума.
- Как только найден подходящий фильтр, его можно и нужно сохранить в файл. Во-первых, это позволяет избежать повторной настройки. Во-вторых, в новых записях возможно не будет фрагмента, который содержат только шум.
- На последнем шаге необходимо применить фильтр ко всему файлу, нажав кнопку "Apply". Если требуется применить фильтр только к определённой части записи, то из окна "Effect - Noise Reduction" можно переключится в основное окно и выделить необходимый фрагмент.
Нужно быть внимательным при выборе части звукового файла, в которой только шум и нет никаких звуков. Дело в том, что если в этом фрагменте окажется какой-то звук, то Adobe Audition будет удалять все похожие звуки по всей записи. Это приведет к появлению неприятных "металлических" призвуков, особенно заметных на музыкальных фрагментах. Также вы можете судить о наличии таких звуков в вашем фрагменте по изломам и всплескам на спектре шума в окне Noise reduction. Обычно график спектра шума представляет собой плавно меняющуюся линию без резких изломов, возможно, с одним или несколькими всплесками в области высоких частот (справа) (в области высоких частот шумы в звуковом тракте видеотехники особо велики: свист и шипение). Если в результате удаления шума возникли такие призвуки, попробуйте отменить операцию ("Edit" > "Undo noise reduction") и повторить всё с самого начала, начиная с выделения фрагмента звука с шумом. Образец шума и очищаемый от шума звуковой фрагмент могут храниться в разных файлах, эти файлы могут иметь разную разрядность: необходимо только чтобы у этих файлов была одинаковая частота дискретизации и количество каналов.
Функция подавления шума в Adobe Audition является универсальной и позволяет с легкостью удалять почти любые шумы. В результате файл, очищенный от шумов, звучит значительно лучше.
6. Удаление ненужных фрагментов
Понятно, что некоторые фрагменты записи будут просто не нужны. Их следует удалить.
7. Удаление пауз